

Flexible Systems for the Next ML Revolution(s)





The environment for machine learning innovation has never been better. Modern GPUs are marvels of supercomputer engineering. And software stacks have raised the level of abstraction for ML implementations, so a network that required tens of thousands of lines of CUDA just a decade ago is now a one-page example in PyTorch. ML scientists can focus less on low-level hacking and more on transformative new ideas.
On the other hand, there’s a hidden danger in letting today’s tools shape the future of ML innovation. Mainstream ML hardware and software has implicitly optimized for mainstream ML models. The advances in performance and expressiveness in a modern ML system stack accrue disproportionately to computational patterns that are already popular. So at the same time that we celebrate these systems advancements, we should be cautious about the hidden bias they introduce into ML innovation.
There is a risk that new, unconventional ideas can “lose” to standard conventions—even when they are fundamentally better. Approaches that stray further from the carefully tuned path of mainstream models can bse—more complex and slower—than standard techniques that the system stack has optimized for. This pattern can exacerbate the file-drawer effect, where important scientific results remain unknown because they fall short of the bar for publication.
Transformative change is of course not the only way that machine learning advances; incremental iteration within the mold of mainstream techniques is also a critical form of innovation. But calcifying the landscape of ML systems runs the risk of suppressing the next revolution in ML capabilities that changes the way we think about building AI—in the same way that the deep learning revolution itself did.
To facilitate the next revolutions in ML, it is not enough to be fast and easy to use. The entire ML system stack, from programming languages to hardware, needs to focus on *flexibility* as a goal coequal with performance and expressiveness. Today’s systems should evolve to maintain their strengths for current methods, while broadening them to enable innovation beyond the conventional parameters.
There are two ways that ML tools can build in *status quo* bias: in software and in hardware. Future ML systems will need flexibility in the way they treat software *operators* and the way they incorporate novel hardware beyond GPUs.
Solving for Software Operator Library Lock-In
One way that ML systems bias toward the status quo is by relying heavily on handcrafted *operator libraries*. Operators in ML frameworks implement computational kernels like matrix multiplication, convolution, softmax, and so on—the basic building blocks that make up any model. ML systems get much of their performance from extremely efficient operator implementations that have been hand-tuned by hardware performance experts. Proprietary operator libraries from vendors, like Nvidia’s cuDNN, represent the best known implementations for a given hardware platform. Mere mortals find it hard to match the performance of these carefully tuned, hardware-specialized operator implementations.
The result is that ML frameworks typically work by combining these existing libraries of operators, not generating their own low-level operator code. Users build models by composing the operators, but they have no influence over the way the operators themselves work. If an ML practitioner can describe their model in a way that maps neatly onto the operators available in cuDNN, for example, the model will be easy to implement and it will run efficiently. If a novel approach relies on a new kind of tensor computation—say, one not in PyTorch’s dozens of Tensor methods—then the only option is to fall back to writing the code by hand. And no option for manual implementation is good: plain Python for loops will be disastrously slow; writing new C++ and CUDA sacrifices portability and is still unlikely to match the extreme efficiency of vendor-tuned operators. The effect is that mainstream frameworks make it easy to use existing, popular computations and discourage straying from these standard building blocks.
Modern ML software stracks have made impressive strides in the flexibility of *inter-operator* composition. The next frontier is to bring the same flexibility to *intra-operator* computation. Frameworks need to keep their ability to incorporate hand-tuned operators while also giving end users the ability to define their own custom computations without sacrificing performance. They should make it possible to build ML models that rely on new tensor manipulations that hardware vendors never anticipated.
The key to this flexibility is compilation: frameworks need to invest in designing compilers that can generate code that is competitive with hand-tuned implementations. TVM’s tensor-level IR (TIR) optimizations are its investment in compiling high-quality code for custom and fused operators. By erasing the distinction between baked-in intra-operator code and flexible intra-operator code, TVM and other compiler-driven system stacks can put scientists in charge of new kinds of models that would be infeasible today.
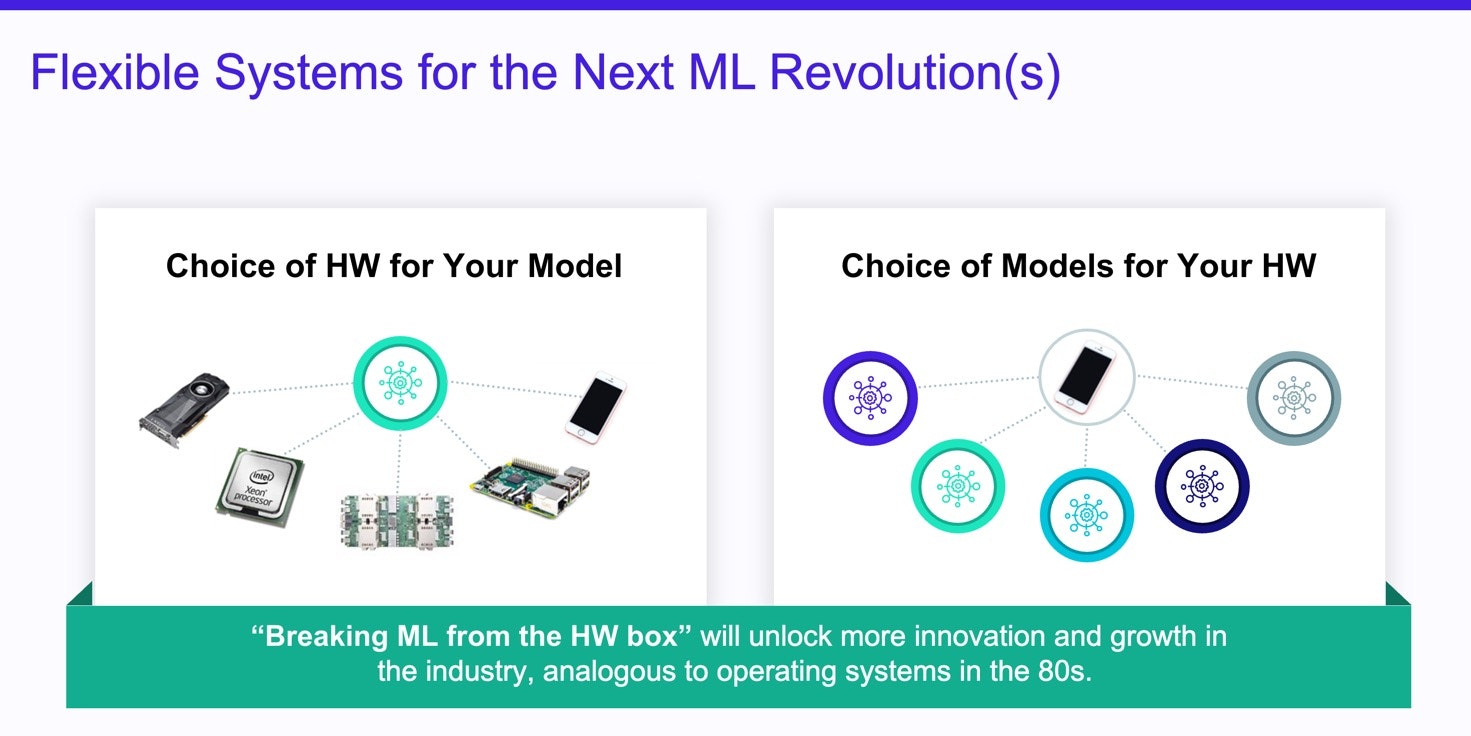
Breaking the Hardware Lottery
Practical ML models today are ones that modern GPUs and CPUs can run efficiently. They build on algorithms that won the hardware lottery, as coined by Sara Hooker: popular algorithms are shaped by the hardware available at the time of their invention. And while GPUs are extremely efficient for certain kinds of computations—they excel at mostly-regular data parallelism with immense throughput demands—they are not the sole model for a high-performance computer architecture.
Over the last decade, however, the death of Dennard scaling and the twilight of Moore’s law have sparked renewed interest in alternative hardware. New, specialized architectures can focus on computational patterns where GPUs are weaker, such as sparsity and irregularity. Exotic alternatives like in-memory computing and wafer-scale integration unlock entirely new performance landscapes. This Cambrian explosion of new hardware will offer different trade-offs than today’s GPU monoculture; different kinds of algorithms will become fast, and approaches that are impractical today will become viable.
The software stack for ML needs to unleash ML scientists to find innovative ways to exploit the post-Moore hardware landscape. In the status quo, however, the only way to use novel hardware is through operator libraries. Hardware vendors will need to write a set of hand-tuned kernels for specific kernels. This approach is exactly backward: it puts hardware vendors in charge of delineating the computations that they believe their hardware will be good for. Instead, ML systems need to put scientists in charge to experiment and discover the unique capabilities of a new hardware platform.
The challenge for the industry is in meeting ML scientists where they are. Software stacks need to preserve the abstraction that has made innovation in GPU-based ML research so productive and bring the same flexibility to all future hardware. The goal should be to let ML scientists focus on the algorithms they want to build, not on satisfying the constraints of the hardware to implement them efficiently. By harnessing the full range of new hardware capabilities, flexible frameworks will be the key to unleashing a post-GPU phase of ML innovation that explores a new and broader landscape of models and algorithms.
Related Posts



At TVMCon this week, we will be presenting our latest research from Carnegie Mellon University and University of Michigan for generating the fastest possible executable for a given machine learning model by using Collage.








By using TVMScript, TVM's embedded domain specific language (DSL), OctoML engineers are able to demonstrate a 20x speedup over a straightforward PyTorch implementation on CPU, and a 1.3x speedup over handwritten CUDA implementation on GPU for a real-world kernel.


