

The Future of Hardware is Software




In this article
In this article
General-purpose GPU computing helped launch the deep learning era. As ML models have grown larger and more computationally intense, however, they have changed the way GPUs are designed—and they have inspired a wave of new hardware that looks radically different from GPUs. From battery-powered embedded devices to high-end datacenters, special-purpose ML hardware is taking over. There are in-house ML accelerators from many of the biggest enterprises in the technology industry (to name a few: Google, Apple, Microsoft, Facebook, and Tesla all have AI hardware). And a new generation of startups has emerged with an outpouring of novel visions for the future of efficient ML hardware. After decades of stability around commodity CPUs, the hardware landscape is exciting again.
The problem with hyper-efficient custom ML hardware, though, is that better hardware alone is not enough. Powerful hardware needs a software stack that makes its power available to applications. Even an accelerator that is 100× faster and more efficient than a mainstream GPU cannot practically replace a GPU if it is impractical to use. Standard hardware has a lengthy head start over any new hardware: engineers and ML scientists already know how to use it, and using it requires zero lines of code to change. To realize their full potential, new ML accelerators need to compete on software as much as hardware.
The importance of software to the success of hardware is not just about ML acceleration. History is full of technically superior hardware that never realized its full potential because of drawbacks on the software side. A classic example is Itanium: it is only a historical footnote today, but Itanium’s explicit parallelism and focus on scalability once made it look like the future of CPUs. The problem was never the hardware itself—it was difficult compilation and backward compatibility with the x86 software ecosystem that doomed Itanium. The emerging generation of ML accelerators needs to focus on the entire system stack to avoid losing the battle to mainstream hardware in the same way.
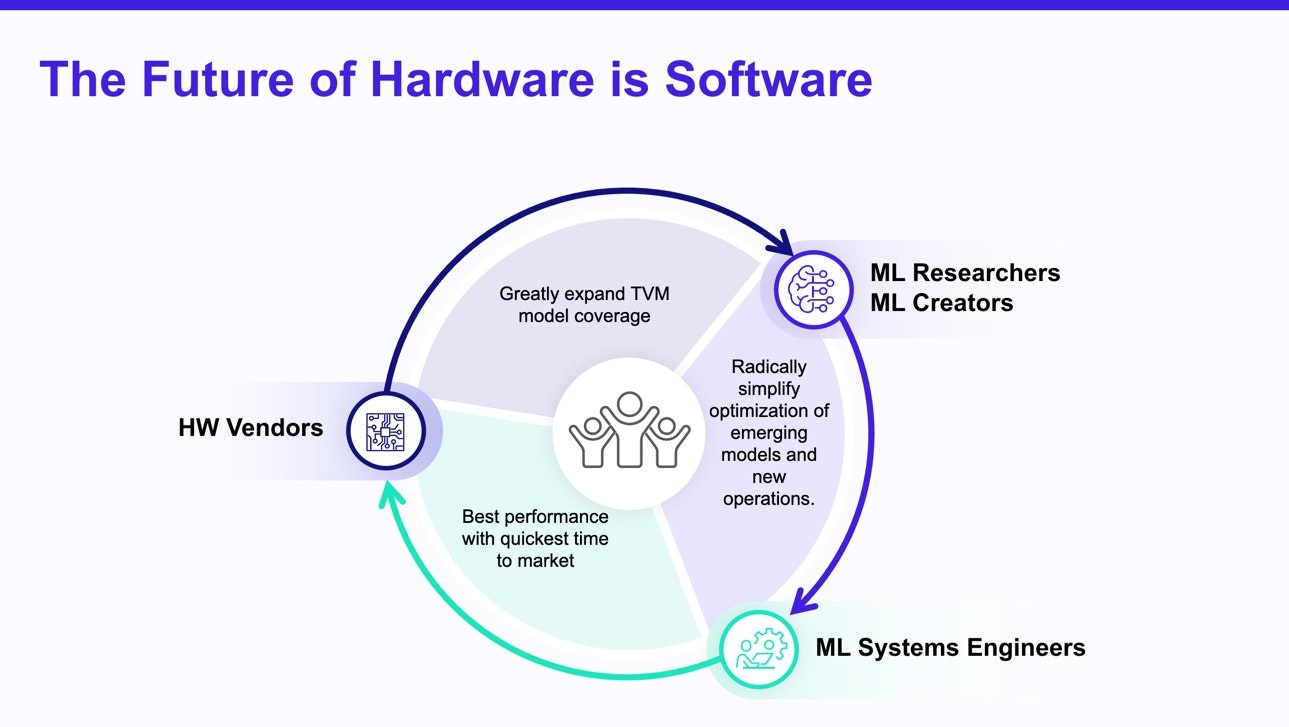
The GPU Moat
Modern GPUs are not just hardware products. When someone buys a GPU for ML computation, they also buy into an entire ecosystem of software built around it. Using mainstream hardware comes with software advantages at three levels: frameworks, libraries, and languages.
- Frameworks: The entire range of modern ML frameworks, from PyTorch to JAX, has first-class support for standard CPUs and GPUs. Any new hardware would need to compete with the sheer simplicity of using all the existing code written for these frameworks. The breadth of these frameworks makes them daunting for new hardware to achieve “GPU parity” by reimplementing all the functionality in a mainstream framework. A complete replacement in PyTorch, for example, would need to cover all 2,239 functions in its native tensor computation interface and keep up with changes in every new release.
- Libraries: Every GPU comes with highly tuned software libraries that extract the best possible performance from the underlying hardware. cuDNN, for example, represents many person-decades of effort spent carefully optimizing important operators for each Nvidia GPU architecture. A dedicated team of experts ensures that cuDNN delivers peak performance from each new GPU architecture on the latest popular ML models. Even if new hardware can theoretically outperform a GPU, it can still lose to that sheer investment of expert software engineering.
- Languages: For low-level performance engineering, applications rely on code written in close-to-the metal programming languages like CUDA. Popular programming languages exert a powerful lock-in effect: they build up valuable developer mindshare over time, and an entire ecosystem of tools grows up around them. From syntax highlighters to interactive debuggers, there are good reasons customers prefer familiar programming environments—even if they come at a performance cost.
Taken together, these advantages mean that shipping a hardware *product* entails much more than building the hardware itself. The breadth and depth of the ecosystem around traditional GPUs means that it is not feasible for any single new hardware vendor to compete on the technical advantages of hardware alone. It is not enough even to tune a cuDNN-like high-performance library and demonstrate it working in a fork of PyTorch, for example—the speed of open-source evolution in ML means that any prototype software stack will soon become out of date.
Hardware vendors who focus exclusively on designing the best possible hardware risk delivering extreme performance only on models from three years ago. To breach the GPU moat, successful hardware projects need a strategy that avoids reinventing the entire traditional ML software stack.
Resisting Lock-In with Open Infrastructure
To show off the capabilities of new hardware, it is tempting to build a software stack *vertically*: to implement a few ML models as end-to-end use cases. Beyond the proof-of-concept stage, however, competing with mainstream GPUs requires building *horizontally*: exposing the hardware’s full range of capabilities to software. Developers need to be able to integrate the new capabilities into an *existing* software stack, not a hardware-specific variant. Applications can adapt to exploit the new capabilities without sacrificing the code, tools, and optimizations they rely on.
Shipping horizontal hardware support requires collaboration. A single-vendor software silo may work in the short term as a demo, but the rate of change in ML science and engineering will quickly render any proprietary stack obsolete. Accelerators need to opt into a shared software stack that spans hardware targets and doesn’t need one-off hacks to support a new platform.
Unlike a proprietary software stack from a single vendor, an open infrastructure fosters a community that keeps the stack nimble and ready for changes in the ML ecosystem. It lets hardware compete on its own merits. Applications can fluidly experiment with different hardware backends and compare their performance—without the artificial barriers of software lock-in, the best hardware wins. And in the coming era of diverse new hardware, no single hardware platform will dominate: applications will need to aggregate ensembles of accelerators with different strengths. To realize the full potential of a heterogeneous post-GPU future, new hardware will need to opt into a fluid and portable software stack.
Related Posts



The environment for machine learning innovation has never been better. Modern GPUs are marvels of supercomputer engineering. And software stacks have raised the level of abstraction for ML implementations...



At TVMCon this week, we will be presenting our latest research from Carnegie Mellon University and University of Michigan for generating the fastest possible executable for a given machine learning model by using Collage.





