

Write Python with blazing fast CUDA-level performance




Imagine you are an ML Scientist setting out to build a brand new model based on the latest and greatest ML research. You develop an innovative new layer which makes the model perform on its specific task more accurately, but it is 10x slower to train.
Do you abandon this model because the training process is prohibitively slow, or continue forward? Continuing forward requires framework modifications, or hand-optimized device specific code which is written in a programming language you may not know well. What if you could solve this problem without ever leaving Python, and integrate the solution into your existing workflow in just a few lines of code? You can do this by using Apache TVM — the open source ML stack for performance and portability — whose mission is to enable access to high performance machine learning anywhere for everyone.
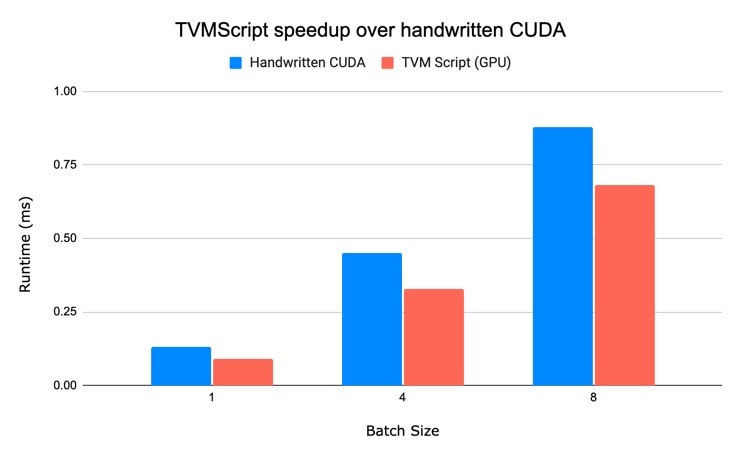
By using TVMScript, TVM's embedded domain specific language (DSL), OctoML engineers are able to demonstrate a 20x speedup over a straightforward PyTorch implementation on CPU, and a 1.3x speedup over handwritten CUDA implementation on GPU for a real-world kernel.
Not only can TVMScript dramatically improve your performance, but it enables you to write straightforward for-loops instead of terse array code. It also provides seamless integration for both CPU and GPU in Python, and mitigates the need to learn a separate application flow.
TVMScript
TVMScript is a new way to use the full power of TVM directly in Python. TVMScript enables end-users to write low-level array programs in a natural loop style and accelerate them. One way to conceptualize this is as a Python-friendly way to write CUDA-like compute code directly. In the coming year, these TVMScript programs will benefit from TVM’s new auto-tuning framework’s ability to automatically optimize for a variety of hardware. For more details on this on-going work on auto-tuning you can check out the recent GTC talk from OctoML.
By moving even the lowest level of device programming APIs into Python it is possible for engineers to quickly inspect, iterate on, and debug code much like what is being done in JAX and PyTorch for higher level computation graphs.
All that is required to get started is a kernel in the TVMScript DSL, and a few lines of code to integrate it with your existing Python code. TVMScript is human readable and editable in Python—making debugging easier. For example, a user can dump intermediate state from compiler passes to understand performance or how code is transformed.
The below code is a simple “Hello World” program of TVMScript. It implements an element wise addition operation over two same sized vectors. TVMScript takes its arguments in an “in-out” style, where what would traditionally be the return value is passed in as an argument as well.



This kernel can then be integrated into any framework which supports the Python Array API standard, which the TVM community helped collaboratively define with the greater Python data science community.
You can JIT compile this kernel directly—it is lowered from your Python code into TVM’s low level TensorIR, then code generated to CUDA, RoCM, LLVM, Vulkan, or any of the many other targets supported by TVM.
Once the kernel is compiled, you can invoke it like a normal Python function and the details will be taken care of for you, including launching the kernel, managing memory, and integrating with Python.



TVMScript is still under active development and we expect it to become more ergonomic and easier to use in 2022, but you can use it now to unlock use cases which are challenging today. A forthcoming feature in TVM, MetaScheduler, will make it possible to better schedule these operations automatically to improve performance. Today, it can be used as a high performance way to compile code for different backends with minimal effort. For example switching annotations to take advantage of specialized parallelization strategies when moving from CPU to GPU, or make use of backend specific intrinsics such as CUDA swizzle operations.
In order to use TVMScript today, you can just install a recent version of TVM, or a community build of TVM called tlc-pack which comes packaged with useful third party libraries.
Deformable DETR as a Longer Case Study
In order to demonstrate how TVMScript can be used to accelerate emerging models we performed a case study on accelerating a layer that is slow in native PyTorch. In particular we focus on a new type of vision transformer model.
Over the past few years the transformer model architecture has become the de facto way to build models in multiple domains. As transformers have grown in popularity there are often adaptations for each domain. One particular evolution is the use of different attention layers. The standard multi-head self-attention is efficiently implementable in many frameworks but often models use a specialized attention mechanism.
The Deformable Detection Transformer, which is a new way of approaching object detection, makes use of a customized attention layer. Although this layer improves model performance considerably its computational efficiency is poorer than the original detection transformer. Large institutions with expert talent and resources like Facebook are able to implement a high performance version of this operation in CUDA, but this is not a reality for most ML Scientists.



We have used TVMScript to reimplement the above kernel. As we pointed out above, the TVMScript implementation provides a 20x speedup over a straightforward PyTorch implementation on CPU, and a 1.3x speedup over a handwritten CUDA kernel on GPU, all via Python code.
You can find an in depth implementation, performance comparison, and code at our repository. Once you have implemented such a kernel you can directly write its gradient as well and expose it as a differentiable operation in PyTorch, thus making use of TVM for both inference and training.
TVMScript is just one way to integrate TVM into your current workflow. There exists multiple mechanisms to connect TVM into deep learning frameworks such as PyTorch. At TVMcon this week there will also be a talk on how use functorch, a new library from Facebook which could bridge the gap between high level PyTorch programs and compilers such as TVM in the future. Expect to see more coverage on framework integration in 2022 from OctoML as well.
TVMScript as Part of TVM Unity in 2022
TVMScript in 2022 has lots of room to continue to grow. TVMScript today represents an initial version of exposing TVM’s full power directly into Python. As we continue to evolve its ergonomics, introduce new capabilities to MetaScheduler, and continue to build more integrations, it will be possible to rapidly write natural high performance kernels that are intelligently adapted to the underlying hardware device, saving time and money, and allowing ML Scientists to focus on innovation instead of limitations.
If you are interested in getting involved you can try out the code presented in this blog, provide more feedback and questions, and help contribute to the underlying technology here. Also if you are interested in driving innovations in the TVM community or in ML acceleration in general, please apply for a position at OctoML.
Related Posts



At TVMCon this week, we will be presenting our latest research from Carnegie Mellon University and University of Michigan for generating the fastest possible executable for a given machine learning model by using Collage.








OctoML, the company behind the leading Machine Learning (ML) Deployment Platform, has recently spearheaded ML acceleration work with Hugging Face’s implementation of BERT to automatically optimize its performance for the “most powerful chips Apple has ever built.”



