OctoStack
OctoAI’s GenAI production stack in your environment.
Overview
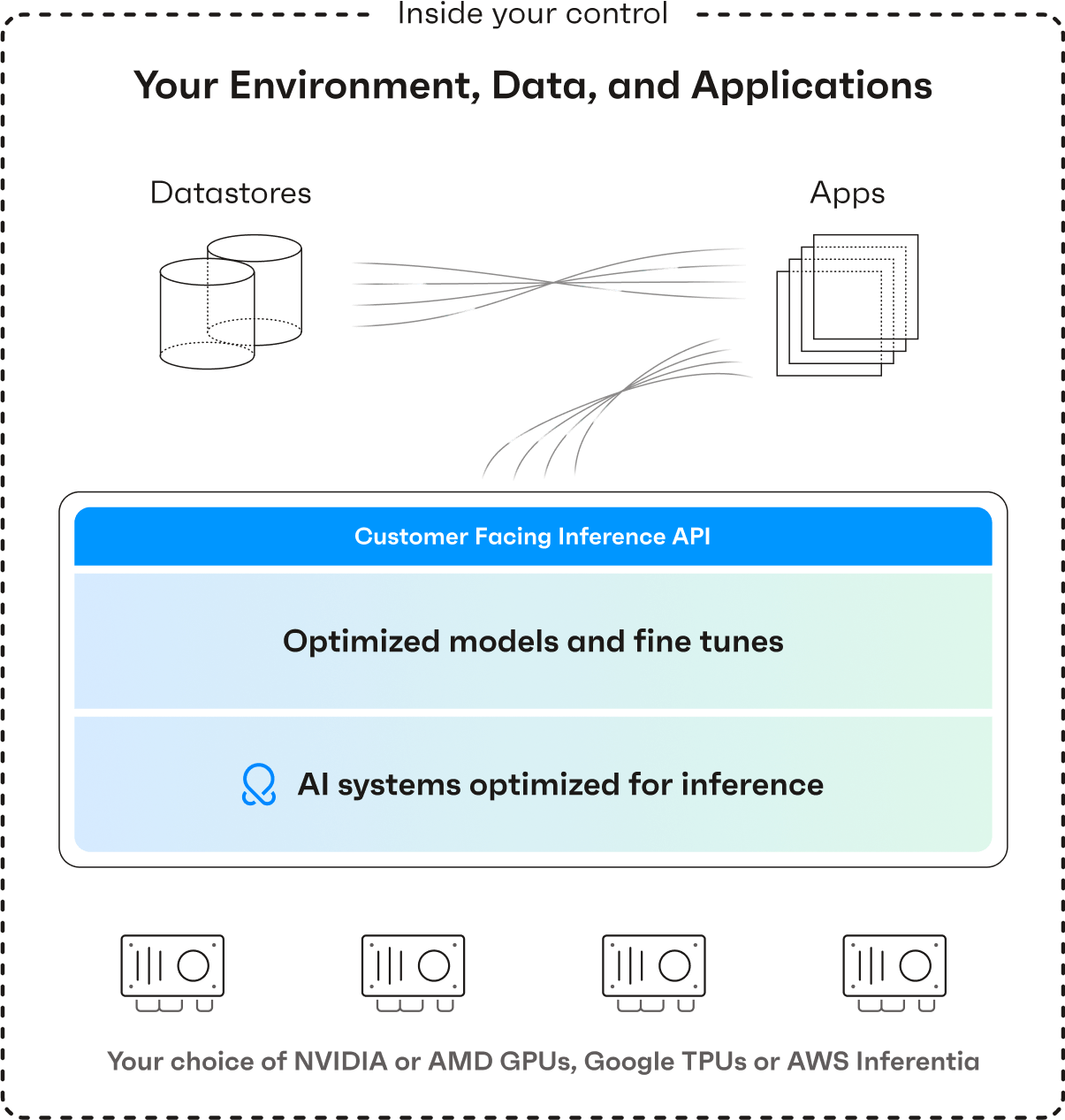
OctoStack is a turnkey generative AI solution allowing you to run your choice of models in your environment. It delivers OctoAI’s industry-leading AI inference service and performance optimizations with the privacy benefits of self-managing within your environment. OctoStack provides a full stack solution for running generative AI at scale - including inference, model customization, load balancing, auto-scaling, and telemetry. OctoStack is compatible with all cloud service providers and container orchestration services.
Key Benefits
Privatey deploy in any environment
OctoStack is designed for portability across any cloud platform or on-premise data center. Prebuilt containers are easily deployed using Kubernetes or your preferred container orchestration service. Maintain complete data privacy and control by processing all generative AI workloads within your environment.
Performance optimized inference
OctoStack includes OctoAI’s performance optimizations delivered through Apache TVM, a compiler framework that optimizes and accelerates inferences. Optimized inference improves GPU utilization and delivers the best possible application experience. OctoStack also provides best-in-class load balancing to operate at scale.
Easy to use APIs & customization
Application developers can use OctoStack’s industry-standard API’s, including Python and Typescript SDK’s. Our ergonomic API’s allow rapid development and integration. You can easily load and run open source models, and fine-tuned checkpoints.
Get Started
Reach out to the team to see a live demo and get started on your OctoStack deployment.
Was this page helpful?