

OctoML helps Woven Planet run ML inference for the next generation of smart technologies





TVM is one of the most important HALs (Hardware Abstraction Layers) for the Arene AI Platform.
Ryo Takahashi, Senior Engineer, Woven Planet
The Challenge: A fast moving ML hardware landscape slows down ML adoption
Many of Woven Planet’s business units run neural networks and the Arene team needed to support inference on a wide range of processors from high-performance to low-power, including CPUS, GPUs and NPUs (Neural Processing Units). Woven Planet chose to work with OctoML to address three challenges they were facing as a consequence of adopting rapidly changing ML hardware.
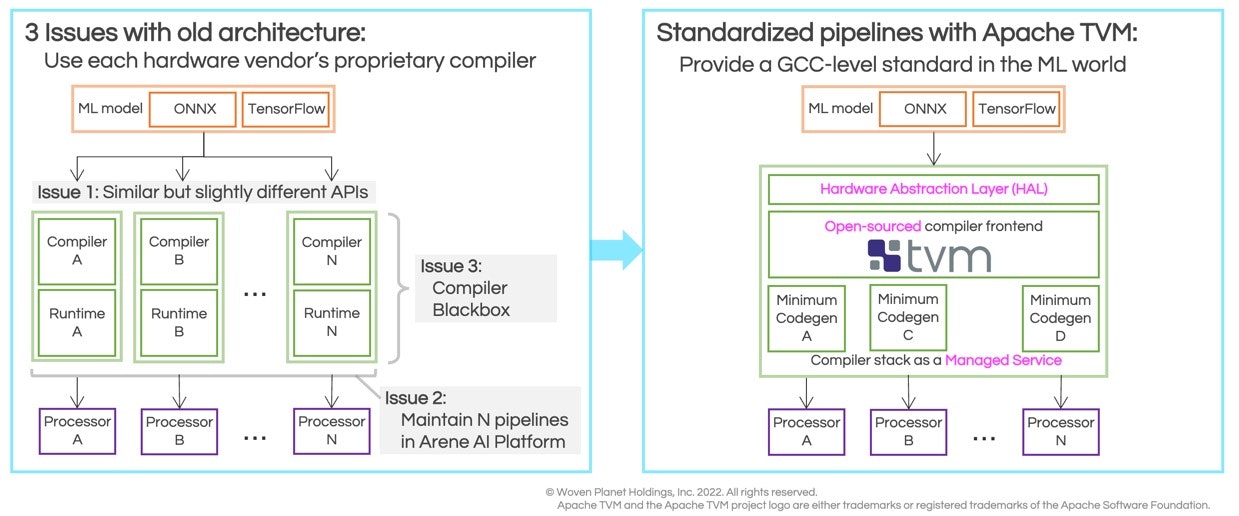
- Similar, but slightly different APIs. Supporting different types of hardware also required integrating different proprietary inference libraries developed by processor vendors. Consequently each additional processor vendor added to the platform introduced a non-reusable inference code with a different API.
- Maintain N pipelines in Arene AI Platform.As the hardware targets grew, and more end to end ML pipelines were also added, the platform became more complex to manage, requiring a huge amount of ML engineering person-hours to maintain. Keeping up with rapidly changing vendor inference libraries introduced a third challenge.
- The compiler blackbox.Woven Planet’s data scientists are working at the cutting edge of deep learning, constantly attempting to create and complete new layers built with new operators to a stable and fast inference runtime. However, proprietary ML compilers and libraries sometimes struggle to keep up with the rapid pace of innovation and when compilation errors occur, the processor vendor typically has to be contacted for support. Black box compilers and proprietary inference libraries therefore slow down the adoption of new deep learning algorithms and hardware targets.
How OctoML and Apache TVM help Woven Planet rapidly adopt the latest ML models and hardware
The solution to an increasingly complex and unmaintainable ML landscape was to adopt Apache TVM, the open source ML stack for performance and portability. After the Arene AI Platform adopted TVM’s inference API, application developers can now use all processors via a single, unified TVM API. This created a kind of Hardware Abstraction Layer over the various hardware platforms, freeing application developers from learning several APIs, reduced the burden of ML engineers from maintaining different proprietary vendor stacks and finally allowed data scientists to realize the innovative algorithmic advances on the latest hardware targets.



A concrete example of the benefits of this tighter innovation loop can be seen in Woven Planet’s advanced mapping software. To support vehicle automation on a global scale, pipelines are continuously generating high-definition maps by fusing anonymized RGC images from cameras in vehicles with satellite imagery. One of the core models used in this solution is a semantic segmentation vision model that is run via batch inference in the cloud on up to hundreds of CPU instances daily.
By leveraging OctoML's SaaS platform, Woven Planet realized as much as 80% reduction in inference times compared to previously adopted deep learning frameworks and 28% reduction in inference versus other inference engines. This directly translated to comparable cost reductions in the cloud.



To learn more about how Woven Planet adopted Apache TVM, check out their recent blog, “TVM in the Arene AI Platform of Woven Planet” and TVMCon 2021 presentation.
If your organization would like to work with OctoML to simplify your ML pipelines while unlocking the latest ML algorithmic innovations and hardware targets, reach out to us.





