

Accelerating machine learning at the edge: Arm Cortex-A72 CPU now available in OctoML





Today we’re excited to announce our partnership with Arm, which highlights our collaboration across a broad array of hardware and embedded systems. This relationship - which spans efforts in Apache TVM open source and our commercial OctoML platform - showcases the expanding ecosystem of partners that OctoML is engaging with to help customers be successful with their machine learning needs. Today, customers are challenged by the complex, yet largely manual effort to accelerate ML models as they attempt to move their trained models into production. Our Machine Learning Deployment Platform provides customers choice, automation, and performance in backing their efforts to cost optimize their inference or create new ML services that weren’t previously possible on IoT and embedded systems.
With that as the broader context, we’re eager to share world-class performance results for Arm Cortex-A72 processors with TVM achieving latency speedup of 1.9x from ONNX Runtime and 2.18x from TensorFlow Lite for a wide range of vision models. These results are a fantastic first step for OctoML as we add Arm-based hardware support to our commercial platform. Anyone can now do the same acceleration for their custom ML models with a few clicks or API calls in the OctoML platform.
What is the Cortex-A72?
The Cortex-A72 processor is a high-performance, low-power 64-bit processor that launched in April 2015 with a focus on efficiency. Arm designed the microarchitecture for the mobile market as a synthesizable IP core that is sold to other semiconductor companies to be implemented in their own chips such as Broadcom’s BCM2711 (used in Raspberry Pi 4), Qualcomm’s Snapdragon 650/652/653, Texas Instruments’ Jacinto 7 family of automotive and industrial SoC processors, and NXP’s i.MX8/Layerscape chips. With its broad adoption, the A-class backs some of the largest edge device categories in the world, from mobile phones, security cameras, autonomous vehicles, IOT devices, wireless and networking infrastructure, and other industry-specific machines.
Machine Learning at the edge is challenging
Running inference for ML models on edge devices comes with many benefits, such as significantly lower cloud computing costs and a faster user experience because data doesn’t have to travel to the cloud and back. But running production-level deep neural network applications on the edge also imposes new constraints on power consumption and compute and memory efficiency, which are more restricted than in traditional cloud environments. Because the models trained in frameworks such as TensorFlow or PyTorch are typically built for cloud-based applications, they can be scaled horizontally in the cloud by adding more servers to meet growing user demands. Edge devices, on the other hand, must make better use of the underlying hardware and meet efficiency requirements by optimizing the model itself for inference.
This is exactly the challenge the OctoML team has been focused on solving through open source collaboration with companies like Arm via the Apache TVM open source ML stack for performance and portability. Now with the addition of Cortex-A72 to the OctoML Machine Learning Deployment Platform, ML engineers get the power of TVM’s cutting edge acceleration techniques with the ease of OctoML’s unified platform--unlocking the ability to accelerate the latest model architectures.
Apache TVM performance on Cortex A72
To understand how Apache TVM’s model acceleration compares to TensorFlow Lite (TF Lite) and ONNX Runtime, we pulled all 25 of the hosted floating point sample models from TF Lite’s pre-trained model zoo. Then we optimized the FP32 models via three different software frameworks using their respective best practices: TVM 0.7 (within OctoML), default TF Lite 2.5.0.post1, and ONNX Runtime 1.8.1.
Our performance benchmarks show that TVM achieves best-in-class performance for a wide range of deep learning vision models, with an average latency speedup of 1.9x from ONNX Runtime and 2.18x from TF Lite.
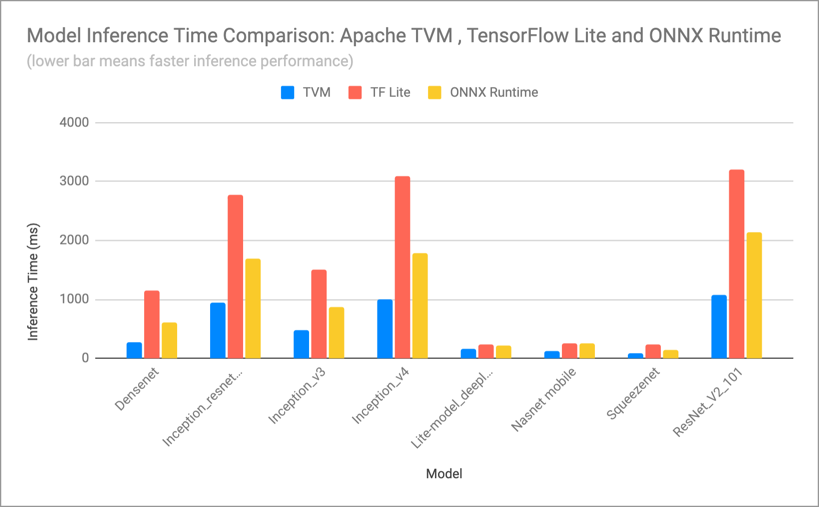
Apache TVM speed ups for computer vision models running on Arm Cortex-A72
The bar chart above shows inference times for a variety of vision models, including DenseNet, Inception, Squeezenet and ResNet from the TF Lite zoo. For example, with DenseNet the TVM-optimized model achieved a 4.2x speedup over TF Lite and a 2.2x speedup over ONNX Runtime.
The next chart below shows all MobileNet vision models for resource constrained devices, from the TF Lite zoo:



Apache TVM speed ups for MobileNet models running on Arm Cortex-A72
In the real world, these speedups translate to reduced inference costs and applications that react faster to incoming sensor data at the edge.
Optimize your ML models for Cortex A-72 in OctoML
With the OctoML Machine Learning Deployment Platform anyone can accelerate models for the Cortex A-72 in just a few clicks or API calls.
The OctoML screenshot below shows both TVM and ONNX Runtime engines selected and Cortex A-72 as the hardware target:



After clicking Accelerate, OctoML starts accelerating the model in parallel using TVM and ONNX Runtime:



Once acceleration has completed, you can easily compare the TVM inference metrics to the ONNX Runtime metrics and download the TVM-accelerated model for deployment to production.
As with all other supported hardware, OctoML accelerated models are available in a variety of easy-to-use packaging formats (Python wheel and Linux shared object) for effortless production testing and deployment
Speed up your models at the edge
Ready to speed up your own models at the edge? Sign up now for a free early access trial to our platform and start running your models quickly and efficiently. In addition to Arm’s Cortex A-72, OctoML also offers model acceleration covering multi-cloud standard CPUs and GPUs, edge GPUs with the NVIDIA Jetson Xavier, edge CPUs with Arm architectures and a robust pipeline of additional devices coming online in the months ahead.
Related Posts


We're excited to share our collaboration with AMD around Apache TVM and our commercial OctoML Machine Learning Deployment Platform. With Apache TVM running on AMD’s full suite of hardware, ML models can run anywhere from the cloud to the edge.





Today, we’re excited to announce a new milestone in the evolution of our platform and ecosystem. We’re officially announcing our first partnership with Qualcomm, an industry leader in mobile hardware technology.

