

Unlocking 10x Performance Improvements on Computer Vision Models




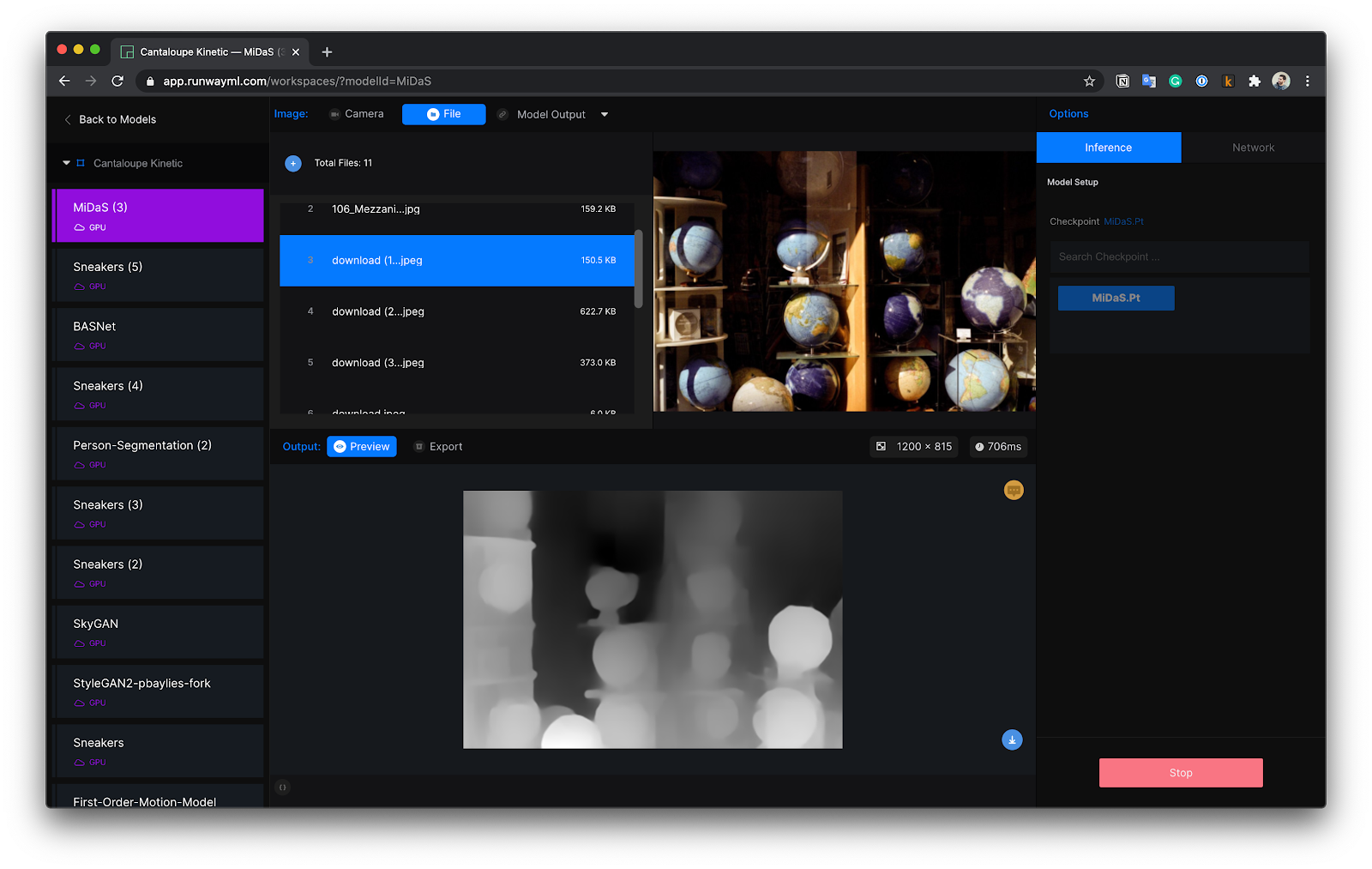
At OctoML, we love working with teams that are changing our world through the application and productization of deep learning models. We recently had the chance to work closely with Runway, which is a next-generation content creation toolkit that enables easy access to many types of deep learning models to designers, filmmakers, and other creators. Runway made use of our Octomizer, which is now in Early Access (you can sign up here).
One of the challenges Runway faces is running many types of models in their cloud environment at reasonable cost — each model has its own startup and inference-serving costs, and when you’re working with thousands of users constantly tweaking and updating their own models, those costs can really add up.
If you’re interested in what they do, you can [sign up for Runway to try out the MiDaS model, or any other of more than 100 machine learning models for image, video, and text synthesis available on the platform.
One of the models that Runway commonly runs is called MiDaS — a monocular depth estimation model, released only last year, that enables users to determine the distance of objects from the camera in two-dimensional video and photos.
As part of their real-time and off-line needs, Runway was looking for two results: first, enabling real-time inferencing to accommodate an interactive product experience, even if that required downscaling their imagery input size. Second, enabling the most efficient inferencing for offline processing, where the inferences per dollar mattered more than throughput (frames per second).
Runway provided their version of MiDaS to us, along with some of their current data on model performance and their product-level requirements (primarily throughput given an input size). They did not provide the weights of their models, which is not necessary for the Octomizer to run its optimizations.
OctoML optimized and evaluated MiDaS on multiple GPU targets to understand the performance threshold for Runway’s real-time needs and the efficiency potential for its offline processing. Unsurprisingly, OctoML showed significant performance improvement compared to ONNX-Runtime (which incorporates TensorRT, NVIDIA’s own graph optimization library) on both the NVIDIA K80 and V100.
We commonly see these kinds of results whenever a deep learning model is relatively new or contains anything other than the most common operators in the most common layouts. Because chip manufacturer kernel teams hand-tune their hardware to optimally handle graphs, their optimizations often lag what is technically possible. (As a side note, this is exactly why we believe that TVM, OctoML’s machine learning-based approach to graph optimization, will continue to demonstrate state-of-the-art performance results).
The results of our optimization and benchmarking speak for themselves — over 2.5x performance improvements on Runway’s initial layout (larger inputs running on K80s) and nearly 10x performance improvements at reduced input size running on the more-powerful V100.



OctoML’s Optimization Increases Throughput on the NVIDIA K80 and V100 (512x512)



OctoML’s Optimization Increases Throughput on the NVIDIA K80 and V100 (224x224)



OctoML provides 3–8X performance improvement over ONNX-RT (512x512)



OctoML provides 8–10X performance improvement over ONNX-RT (224x224)
As interesting as these technical improvements are, we also identified some useful product-level implications. Using spot pricing of the various GPU targets, we helped Runway identify the throughput-per-dollar benefit of our optimizations. This analysis helped identify that an efficiency and performance tradeoff existed, with the less expensive, though less powerful, NVIDIA K80 providing the most throughputs-per-dollar (higher is better).



OctoML provides up to 10X throughput-per-dollar performance
We routinely engage in this kind of optimization validation with interested organizations, so if you’d like to explore use of the Octomizer and its optimization, benchmarking, and packaging capabilities, we are currently in Early Access, so please get in touch!
Related Posts



Apache TVM democratizes efficient machine learning with a unified software foundation. OctoML is building an MLops automation platform on top of it.





Apple’s release of an Arm-based chip, called the M1, was a seismic shift in the personal computing landscape.
