

Free pre-accelerated Model Zoo streamlines choice of model and cloud/edge targets










In this article
In this article
This week at TVMCon, OctoML is launching a model zoo with pre-accelerated, ready-to-download vision and language models. Running extremely fast, sub-millisecond models in production is now easier than ever, whether in the cloud or at the edge. For the first time, ML Engineers have a single source for model performance evaluations across a wide array of common cloud and edge hardware targets. The performance benchmarking insights the OctoML platform now visually provides will dramatically simplify the cumbersome model and hardware target selection process for all of our customers.
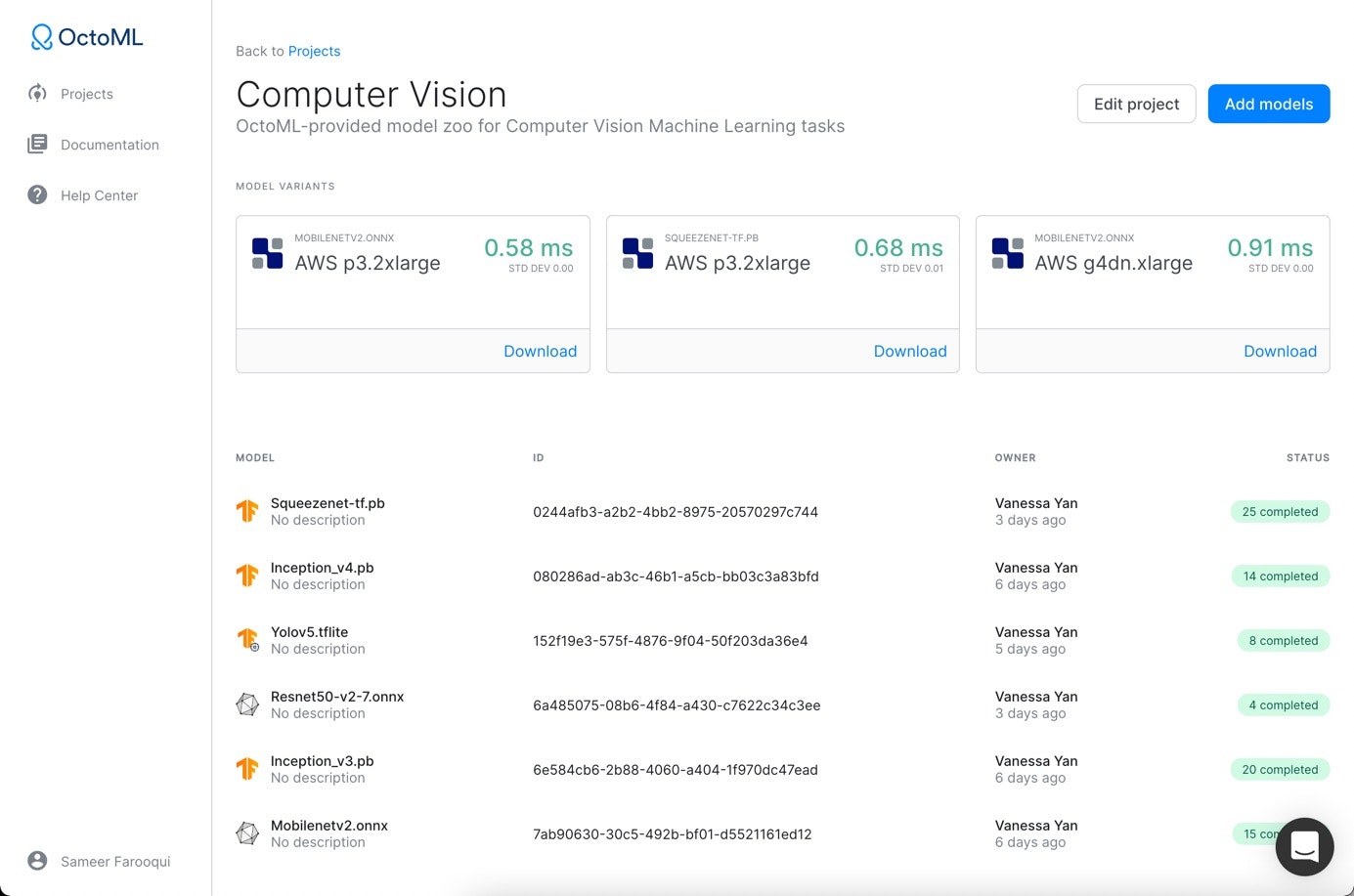
The OctoML model zoo includes:
A Computer Vision (Object Classification and Image Detection) set that includes Resnet, YOLO, Mobilenet, Inception, and more.
A Natural Language Processing (NLP) set that includes BERT, GPT-2, and more.
How fast are the pre-accelerated models?



Our preview performance data for the public models we are evaluating for the OctoML model zoo shows a geometric average speedup across the computer vision (CV) set of 2.2x. This means that employing these models in production would only require half the cost and half the energy consumption of their TensorFlow 2.6 baselines. And more specifically when we look at the pre-accelerated CV set:
GPU speedup average is 2.94x
CPU speedup average is 2.04x
The OctoML Platform excels in providing performance portability and choice which is why these models have been automatically accelerated across an array of hardware targets (which is reflected in the model x hardware comparison chart above) including NVIDIA, Intel, and AMD in the leading clouds: Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure. They are also available on Arm and NVIDIA edge devices. The set of pre-accelerated models allows trial customers to quickly assess what hardware choice might provide the best speedup for them. They are guided through a comparison workflow that benchmarks these models against their TensorFlow or TensorFlow Lite baseline--whatever is applicable for a given workload and hardware target.



This capability rapidly progresses users through the initial trial step that most of them currently take, which is to explore how successful OctoML is in terms of speeding up popular models. This is also valuable to users because it provides actionable data to help them decide which model architectures and hardware targets are suitable for their product and business needs. Users will be able to download an optimized package of the model, including the necessary runtime, and run the model in the cloud of their choice.
The model zoo provides a very significant proofpoint for customers, with an average of 2.2x speedups, because many commonly benchmarked models, like ResNet and BERT, are already heavily hand-tuned by the leading hardware providers. In practice, OctoML's automated acceleration techniques are even more powerful for proprietary customer models – the pre-accelerated benchmarks available in the platform often serve as the floor for performance improvements users can expect. For instance, using the same model acceleration techniques, OctoML was able to help achieve major speedups for Microsoft’s Watch For team, which runs a massive bulk video analysis model that processes millions of hours of video and billions of images a month. OctoML was able to speed up those heavily deployed models 1.3-3X without changing its accuracy! Microsoft is putting those models into production now to drive significant inference cost savings.
To access OctoML's benchmarked model performance on cloud and edge targets here are the three steps starting with our start for free sign up.



Related Posts



OctoML, the company behind the leading Machine Learning (ML) Deployment Platform, has recently spearheaded ML acceleration work with Hugging Face’s implementation of BERT to automatically optimize its performance for the “most powerful chips Apple has ever built.”







Today we’re excited to announce our partnership with Arm, which highlights our collaboration across a broad array of hardware and embedded systems.
